
 Scrapoxy
Scrapoxy


🕸️
All-in-One Providers
Support datacenter providers, proxies services, hardware providers and free proxies list.
Never be blocked. Again.
Aggregate all your proxies in one place and create a consistent webscraping strategy.

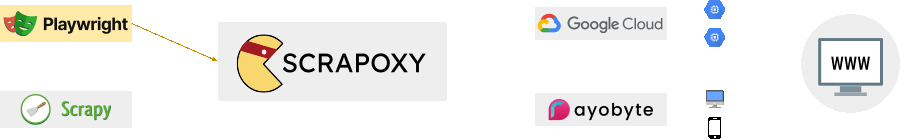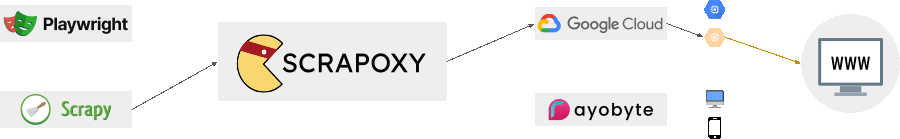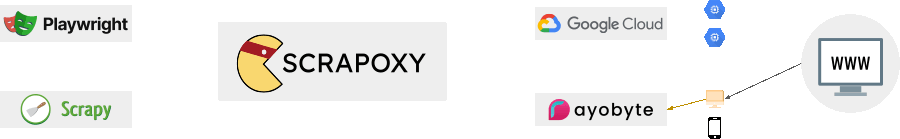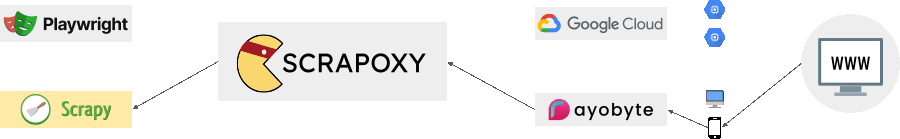
$ docker run -d -p 8888:8888 -p 8890:8890 -v ./scrapoxy:/cfg \ -e AUTH_LOCAL_USERNAME=admin -e AUTH_LOCAL_PASSWORD=password \ -e BACKEND_JWT_SECRET=secret1 -e FRONTEND_JWT_SECRET=secret2 \ -e STORAGE_FILE_FILENAME=/cfg/scrapoxy.json \ fabienvauchelles/scrapoxy
















