
 Scrapoxy
ScrapoxyScrapoxy
What is Scrapoxy?
Scrapoxy is a super proxies manager that orchestrates all your proxies into one place 🎯, rather than spreading management across multiple scrapers 🕸️.
Deployed on your own infrastructure, Scrapoxy serves as a single proxy endpoint for your scrapers.
It builds a pool of private proxies from your datacenter subscription 🔒, integrates them with proxy vendors 🔌, manages IP rotation and fingerprinting, and smartly routes traffic to avoid bans 🚫.
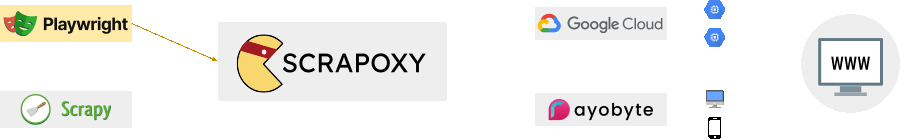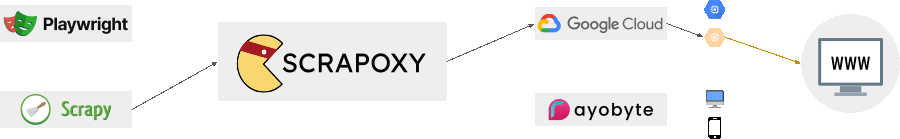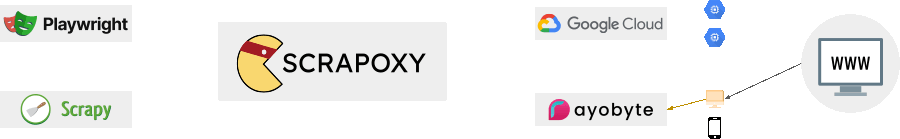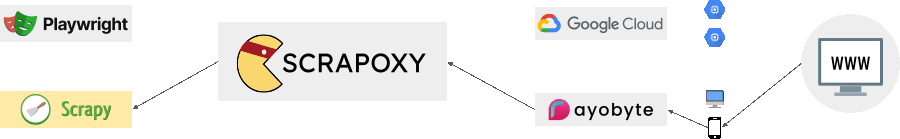
What is not Scrapoxy?
Scrapoxy is not:
- a proxies list manager like ProxyBroker2;
- a webscraper like Scrapy, Crawlee or Octoparse;
- a cloud provider like AWS, GCP or Azure;
- a browser farm like Puppeteer, Selenium or Playwright;
- a proxy service like Rayobyte, IP Royal or Zyte.
What you can do with Scrapoxy?
- Integrate it into your web scraping stack to manage proxies, whether as an individual or a company;
What you cannot do with Scrapoxy?
- Use it for any activities that are illegal under your jurisdiction;
- Get, update or redistribute the source code;
- Sell Scrapoxy.
Features
☁️ Datacenter Providers with easy installation ☁️
Scrapoxy supports many datacenter providers like AWS, Azure, or GCP.
It installs a proxy image on each datacenter, helping the quick launch of a proxy instance. Traffic is routed to proxy instances to provide many IP addresses.
Scrapoxy handles the startup/shutdown of proxy instances to rotate IP addresses effectively.
🌐 Proxy Services 🌐
Scrapoxy supports many proxy services like Rayobyte, IPRoyal or Zyte.
It connects to these services and uses a variety of parameters such as country or OS type, to create a diversity of proxies.
💻 Hardware materials 💻
Scrapoxy supports many 4G proxy farms hardware types like Proxidize.
It uses their APIs to handle IP rotation on 4G networks.
📜 Free Proxy Lists 📜
Scrapoxy supports lists of HTTP/HTTPS proxies and SOCKS4/SOCKS5 proxies.
It takes care of testing their connectivity to aggregate them into the proxy pool.
⏰ Timeout free ⏰
Scrapoxy only routes traffic to online proxies.
This feature is useful with residential proxies. Sometimes, proxies may be too slow or inactive. Scrapoxy detects these offline nodes and excludes them from the proxy pool.
🔄 Auto-Rotate proxies 🔄
Scrapoxy automatically changes IP addresses at regular intervals.
Scrapers can have thousands of IP addresses without managing proxy rotation.
🏃 Auto-Scale proxies 🏃
Scrapoxy monitors incoming traffic and automatically scales the number of proxies according to your needs.
It also reduces proxy count to minimize your costs.
🍪 Sticky sessions on Browser 🍪
Scrapoxy can keep the same IP address for a scraping session, even for browsers.
It includes HTTP requests/responses interception mechanism to inject a session cookie, ensuring continuity of the IP address throughout the browser session.
🚨 Ban management 🚨
Scrapoxy injects the name of the proxy into the HTTP responses.
When a scraper detects that a ban has occurred, it can notify Scrapoxy to remove the proxy from the pool.
📡 Traffic interception 📡
Scrapoxy intercepts HTTP requests/responses to modify headers, keeping consistency in your scraping stack. It can add session cookies or specific headers like user-agent.
📊 Traffic monitoring 📊
Scrapoxy measures incoming and outgoing traffic to provide an overview of your scraping session.
It tracks metrics such as the number of requests, active proxy count, requests per proxy, and more.
🌍 Coverage monitoring 🌍
Scrapoxy displays the geographic coverage of your proxies to better understand the global distribution of your proxies.
🚀 Easy-to-use and production-ready 🚀
Scrapoxy is suitable for both beginners and experts.
It can be started in seconds using Docker, or be deployed in a complex, distributed environment with Kubernetes.
🔓 Free 🔓
Scrapoxy is free, only pay for support.